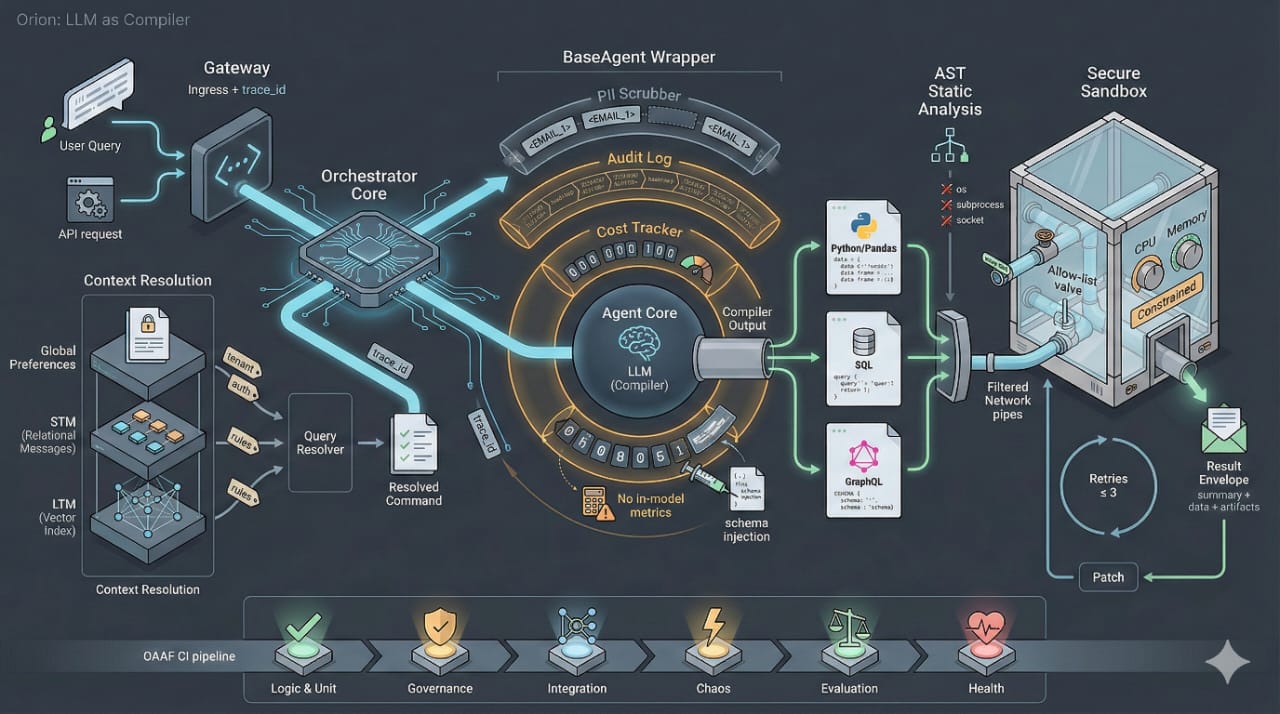
Orion at a glance
- Core principle: LLMs act as compilers, not calculators. They translate intent into Python/Pandas, SQL, or GraphQL, but never compute business metrics directly.
- Determinism: For invariant data and configuration, the same query yields the same code path and the same result.
- Scale: New agents are thin, domain-specific layers over a shared orchestrator, memory stack, governance wrapper, and sandbox runtime.
- Cost: Compute happens in optimized engines (databases, data warehouses, APIs), while LLM usage is constrained via schema injection, minimal context, and bounded retries.
Request lifecycle and system architecture
From user query to routed intent
- Ingress & tracing
- A client (chat UI, API client) sends a request over a persistent connection.
- The gateway authenticates the user (e.g., JWT) and assigns a trace_id that propagates through all downstream systems.
- Context resolution (Memory stack)
Orion’s context system resolves ambiguity and injects business rules before an agent sees the query:- Global preferences (system context)
- Immutable rules such as “report currency in GBP” or “hide cost price columns”.
- Applied to every request for a given tenant or environment.
- Short-term memory (STM)
- Backed by a relational store (messages table).
- Provides conversational context (e.g., resolving “it” to “the red T-shirt from the last turn”).
- Long-term memory (LTM)
- Backed by a vector index (e.g., pgvector in PostgreSQL) for semantic lookup of business rules and definitions.
- Typical usage: map “revenue” to its canonical definition and fiscal calendar for a given organization.
- Global preferences (system context)
- Routing and ambiguity handling
- An intent classifier takes the resolved command and selects a domain, such as SALES, MARKETING, or TRAFFIC.
- An ambiguity / HITL detector checks for missing required slots (metric, time period, dimension).
- If the query is underspecified or classifier confidence is low, the orchestrator pauses the flow and triggers a synchronous human-in-the-loop clarification (e.g., via WebSocket message).
- Once clarification is received, the query is re-synthesized and forced through to execution without re-classification.
- Agent selection
- The orchestrator instantiates the correct BaseAgent subclass (SalesAnalyst, DataAnalyst, etc.) and injects a context object:
- Resolved query.
- Business rules (LTM chunks).
- Global preferences.
- Auth context and per-tenant configuration.
- The orchestrator instantiates the correct BaseAgent subclass (SalesAnalyst, DataAnalyst, etc.) and injects a context object:
Agent runtime: LLM as compiler
The BaseAgent template and governance wrapper
All agents inherit from an abstract BaseAgent; its execute() method is sealed and implements the Template Method pattern:

- PII scrubbing
- Input payloads are passed through a PII scrubber (e.g., Presidio-style anonymization) that:
- Detects PII entities (names, cards, emails, etc.).
- Replaces them with reversible tokens (
<CREDIT_CARD_1>) before any LLM call.
- A bi-directional map between tokens and real values is stored in a secure, short-lived store.
- Input payloads are passed through a PII scrubber (e.g., Presidio-style anonymization) that:
- Audit logging
- The audit service records:
- trace_id, tenant_id, user_id (pseudonymized if necessary).
- Input query (post-scrub).
- Generated code (Python/SQL/GraphQL).
- Execution metadata (latency, cost, error traces, artifacts).
- Logs are append-only and write-only for most components, giving you a “black box recorder” for incident analysis.
- The audit service records:
- Cost tracking
- Token usage and downstream API calls are measured and normalized to cost_usd.
- Cost is associated with trace_id, agent, tenant, and model version, enabling cost per feature or per intent reporting.
Only after these wrappers run does the request reach the agent-specific logic.
Domain-specific logic and schema injection
Each concrete agent defines:
- DSPy-style signatures (input/output schemas)
- Inputs: fields such as
query_text,business_rules,database_schema,time_range,dimensions. - Outputs: a strongly-typed structure containing at least code (string), optional explanation, and metadata such as intended data source.
- These signatures replace ad-hoc prompts with declarative, type-like contracts that can be reused and systematically optimized.
- Inputs: fields such as
- Domain schema injection
- At runtime, the orchestrator passes only the relevant schema snippet into the agent context:
- Example: Shopify GraphQL schema for a sales agent, BigQuery table schemas for a data warehouse agent.
- This shrinks the LLM context window, reduces hallucinated fields, and lowers token usage.
- At runtime, the orchestrator passes only the relevant schema snippet into the agent context:
- Logic engine behavior
- The agent treats the LLM as a code generator:
- Compile the resolved command + schemas + business rules into deterministic code.
- No in-model aggregation or arithmetic; all metrics come from subsequent execution.
- The agent treats the LLM as a code generator:
- Tool isolation
- Each agent holds its own client instances (e.g.,
ShopifyClient,WarehouseClient) with scoped credentials. - Agents cannot access each other’s clients or secrets, enforcing least privilege even as more agents are added.
- Each agent holds its own client instances (e.g.,
Self-healing executor
Once code is generated:
- Static analysis (AST)
- Parse the code and reject it if:
- Forbidden imports are present (
os,socket,subprocess, etc.). - Disallowed patterns appear (file writes outside sandbox directories, network calls to non-allow-listed domains).
- Forbidden imports are present (
- Parse the code and reject it if:
- Sandbox submission
- If AST checks pass, code is sent to the secure sandbox (see below).
- On errors (syntax/runtime), the executor captures stderr and, within limits, re-prompts the LLM to patch the code:
- Retry count is capped (e.g., 3 attempts).
- Error context is filtered to avoid leaking secrets back into the prompt.
This “self-healing” loop dramatically reduces manual debugging of prompts yet keeps behavior bounded for cost and safety.
Secure sandbox and execution environment
Isolation and constraints
The sandbox is a controlled environment where generated code runs:

- Isolation mode
- Development: subprocess + temporary directory.
- Production: lightweight VMs or container sandboxes, with kernel-level isolation to protect the host.
- Context injection
- The orchestrator serializes all inputs (data frames, parameters, config) to a
context.jsonfile inside the sandbox. - Boilerplate code at the top of the generated script reads this context instead of relying on shared memory or global variables.
- The orchestrator serializes all inputs (data frames, parameters, config) to a
- Resource limits and network policy
- Hard timeouts on runtime (e.g., 60 seconds).
- Strict network allow-list: code can call only pre-approved domains (e.g., organization APIs, Shopify, analytics backend).
- CPU/memory caps for noisy-neighbor protection in multi-tenant environments.
- Output capture
- The sandbox collects:
- stdout/stderr.
- Generated artifacts (CSV, JSON, charts as files).
- A normalized result object is returned to the orchestrator:
- The sandbox collects:
{
"summary": "str",
"data": <tabular or structured payload>,
"code": "generated source",
"execution_trace": {
"latency_ms": ...,
"retries": ...,
"artifacts": [...]
}
}This normalized shape is critical for platform-scale composability: dashboards, notebooks, and downstream APIs can all consume the same envelope regardless of agent type.
OAAF: the Agent Assurance Framework
Orion’s Agent Assurance Framework is a CI pipeline for agents. An agent does not ship until it passes all six stages.

1. Logic & Unit
- JSON/structure check: Asserts that LLM output conforms to the contract defined by the agent’s signature(s).
- Tool mocking: Runs generated code against fake or stubbed API clients, covering edge cases.
- Determinism check: Executes the same prompt multiple times verifies stable code generation.
2. Governance
- PII leak test: Checks that audit logs contain only redacted tokens.
- Audit trail check: Verifies contiguous chain of logs for the same trace_id.
- Cost tracking check: Ensures cost entries are recorded and non-zero.
3. Integration
- Routing matrix: Runs a confusion matrix of queries to ensure accurate routing.
- Context injection tests: Tests STM and LTM retrieval.
- Orchestrator sync: Validates output envelope compatibility.
4. Chaos (failure scenarios)
- Garbage input: Fuzz testing with random strings.
- Impossible requests: Inputs like “revenue for year 2050”.
- Simulated upstream failures: Mocked 5xx and timeouts.
5. Evaluation (LLM judge + ground truth)
- Golden dataset: Runs agents against curated Q/A pairs.
- Retrieval-augmented generation assessment: Ensures faithfulness.
- Safety scan: Static analysis for safety.
6. Health check
- Latency: Measures end-to-end p95 response time.
- Memory leak detection: Stress tests repeated calls.
- Shadow mode: Deploys agents to production in “observe only” mode.
Using Orion to build agents at scale
Agent onboarding workflow
For an engineering team, adding a new agent typically looks like:
- Define the domain and intents: Specify intent patterns and example queries.
- Model the schema and tools: Enumerating source systems and building typed clients.
- Design DSPy-style signatures: Defining Input and Output fields.
- Implement the agent subclass: Plugging signatures into BaseAgent.
- Author OAAF tests: Unit, Governance, Integration, Chaos, etc.
- Roll out via shadow mode: Deploy behind a feature flag.
Because governance, sandboxing, and orchestration are shared, most of the work per agent is domain modeling and test authoring, not “prompt hacking.”
Cost and performance considerations
- Compute locality: Let databases do the heavy lifting.
- Context minimization: Strict schema injection.
- Caching: Cache vector retrieval results.
- Deterministic flows reduce re-runs: Stable code paths lower aggregate cost.