Orion: Deterministic Analytics Agents at Scale
Callout: The Orion principle
LLMs translate intent into executable steps (code). The system produces the answer by executing those steps against source-of-truth data—so results are repeatable and reviewable.
Modern organizations want AI that can answer business questions instantly—revenue, growth, funnel conversion, inventory health—without the overhead of manual dashboards and ad-hoc SQL. But they also want the same things they expect from finance systems and BI: consistent definitions, audit trails, and numbers that reconcile.
That’s where most AI assistants struggle. They can summarize and explain, but when the question becomes quantitative, the system either:
- guesses (hallucinates),
- drifts between runs,
- or becomes expensive due to repeated retries and long context.
Orion is built to solve those problems by redesigning the agent workflow around deterministic execution. Orion uses the LLM as a logic engine that compiles a user’s intent into deterministic code (Python/Pandas, SQL, or GraphQL). The actual computation happens outside the model, in a sandboxed runtime that can be governed, tested, and audited.
Below is a practical, easy-to-grasp walkthrough of how Orion works, why it scales, and how it keeps costs low—plus two examples that match common business use cases.
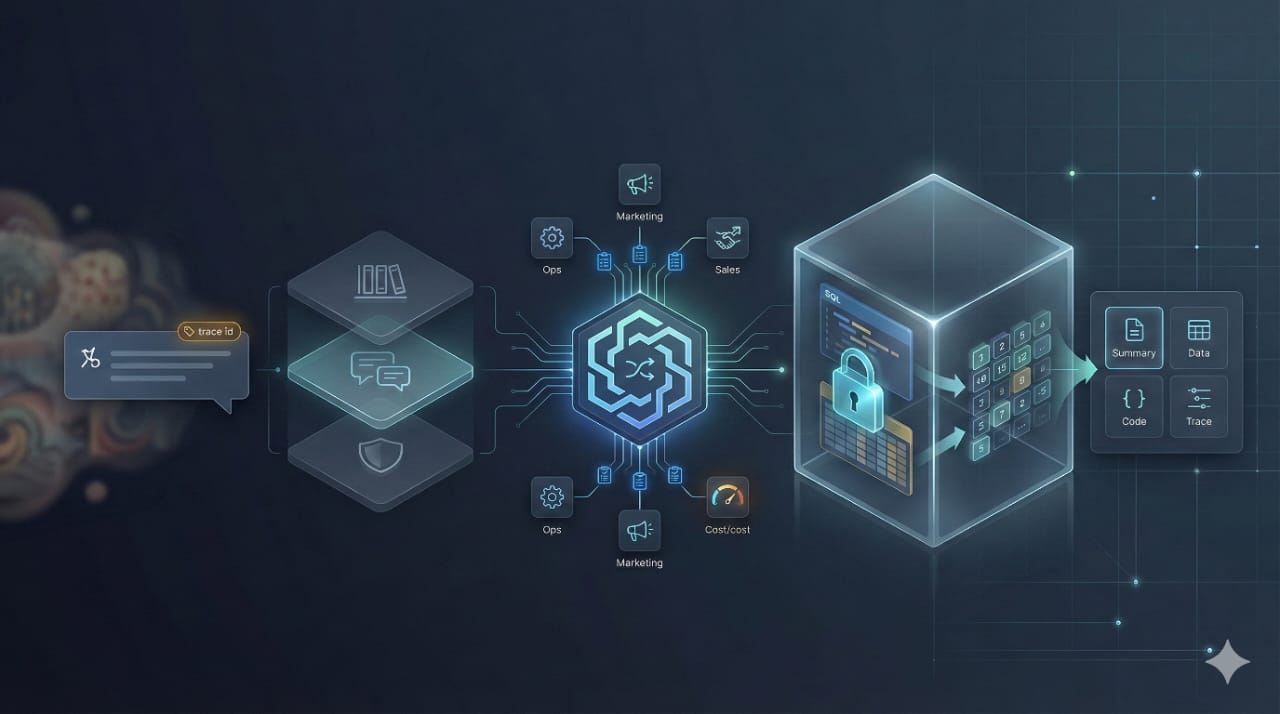
Diagram: End-to-end architecture
This diagram shows the main runtime pieces: context management (memory), orchestration/routing, governed agent runtime, and secure execution against external systems.

At a high level, Orion looks like this:
- Gateway: Authenticates and assigns a trace ID for end-to-end tracking.
- Intelligence Orchestrator: Central controller that gathers context, resolves ambiguity, routes to the right agent, and enforces consistent output.
- Memory system:
- Global preferences (always-on rules)
- Short-term memory (recent conversation)
- Long-term memory (business definitions and policies)
- Agent runtime:
- A shared “BaseAgent” wrapper enforces privacy, audit logging, and cost tracking.
- Specialized agents implement domain logic (Sales, Marketing, Ops).
- Secure sandbox: Runs generated code with strict limits and captures outputs and artifacts.
The key insight: Orion is a platform for many agents. New agents do not reinvent governance, logging, and execution safety—they inherit it.
Why “deterministic execution” matters
If two people ask “How much revenue did we make this month?” they expect the same answer—not one that varies based on phrasing or randomness.

Orion achieves this by separating:
- Understanding (natural language → intent + constraints)
from
- Truth production (deterministic code execution → numbers)
This is the core trade: Orion focuses on correctness and repeatability over improvisational responses.
Callout: What makes Orion different
Traditional assistants generate an answer. Orion generates a runnable plan and then executes it in a controlled environment.
The Orion request lifecycle (plain English)
1) A request enters with accountability built in
A client sends a query (“Revenue this month?”). Orion assigns a trace ID that follows the request through every step—routing, code generation, sandbox execution, and final response. This trace is the backbone for auditing, debugging, and cost control.
2) Orion gathers context before deciding what to do
Orion reduces ambiguity upfront using three layers of context:

- Global preferences
Organization-level constraints like:- currency = GBP
- default timezone = IST
- hide cost-price columns
- restrict to certain business units
- Short-term memory (STM)
Recent conversation history so follow-ups work:- “Show this month’s revenue.”
- “Now break it down by region.”
- Long-term memory (LTM)
Company rules and definitions:- “Revenue = Gross Sales − Refunds”
- fiscal calendar rules
- whether discounts and taxes are included
- “active customer” definition
This is where organizations often disagree internally; Orion tries to make those definitions explicit and consistently applied.
3) Orion routes to the right specialist (and asks when unclear)
Next, the Orchestrator routes the request to a specialized agent:
- Sales questions → Sales agent
- Marketing attribution → Marketing agent
- Inventory → Ops agent
If the question is underspecified, Orion pauses and asks for clarification (human-in-the-loop) rather than guessing.
Callout: Orion asks instead of guessing
If “this month” is ambiguous (calendar vs fiscal) or “revenue” has multiple definitions, Orion asks a quick follow-up question and proceeds once clarified.
4) The agent generates code—not the final number
The agent uses an LLM to compile intent into code:
- SQL query
- Python script (often using Pandas)
- GraphQL query for SaaS systems (Shopify, etc.)
The LLM is treated like a compiler: its job is to produce valid, constrained instructions that match the schema and business rules.
5) The code runs in a secure sandbox
The generated code runs in a sandbox with:
- timeouts (prevents runaway queries),
- restricted network destinations (only approved domains),
- isolated filesystem,
- captured stdout/stderr,
- captured artifacts (CSV/JSON output files).
That execution step produces the answer deterministically.
6) Orion returns a results-ready payload
Instead of returning only a sentence, Orion returns a structured response that can power real workflows:
- Summary: plain-language explanation for business users.
- Data: table(s) or dataset used for the summary.
- Code: what was executed (SQL/Python/GraphQL).
- Execution trace: timing, retries, artifact locations, and metadata.
This makes Orion’s output actionable: you can reuse it in dashboards, scheduled reporting, and approvals.
Scaling to many agents without chaos
Orion is built to create lots of agents safely. The trick is that each agent is relatively small because the platform supplies the hard parts.
What stays the same for every agent
- privacy protection (PII scrubbing),
- audit logging,
- cost tracking,
- sandboxed execution,
- output envelope format,
- orchestration and routing pattern,
- memory injection.
What changes per agent
- which tools it can call (Shopify, database, warehouse, internal APIs),
- which schema it sees (only relevant fields),
- which business rules apply most often,
- which intent routes to it.
This structure makes agent creation scalable across teams: an org can add new agents without re-litigating governance and security each time.
Example 1: “How much did we make this month?”
Here’s what happens behind the scenes when a user asks:
User: “How much did we make this month?”
Step A: Clarify the definition (if needed)
Orion checks LTM for the organization’s rule:
- Revenue definition (e.g., Gross Sales − Refunds)
- fiscal month definition (calendar month vs fiscal period)
If it’s unclear, Orion asks:
- “Do you mean net revenue (after refunds) or gross sales?”
- “Calendar month or fiscal month?”
Step B: Compile the plan into deterministic code
Once clarified, the Sales agent generates:
- a data fetch step (Shopify API / database query),
- a calculation step (aggregate gross and refunds),
- formatting rules (GBP, rounding policy).
Step C: Execute in sandbox and return results
The sandbox runs the code and produces:
- revenue number,
- supporting table(s) (daily revenue, refunds),
- an artifact like
revenue.csv, - a short business-friendly summary.
Callout: Why this is more reliable than a chatbot
Orion’s number is the output of executed code against your source data, not a model’s best guess.
Example 2: “Show top products by region”
User: “What are our top products by region this month?”
This request is a great test of agent scale because it includes:
- metric (sales / revenue / units),
- time window (“this month”),
- breakdown (region),
- ranking (“top products”).
Step A: Slot completion
If anything is missing, Orion asks:
- “Top by revenue or units sold?”
- “Which region dimension: shipping country, billing country, store region?”
Step B: Generate code with constrained schema
The agent sees only relevant fields:
- order total, refunds, product line items,
- region dimension,
- timestamps.
Then it generates a query that:
- filters to the month,
- groups by region and product,
- sorts and returns top N.
Step C: Deliver a usable output
Orion returns:
- a short explanation,
- a ranked table per region,
- a CSV that can be shared,
- the query/script that produced it.
This is “results-ready”: it can be dropped into a weekly ops review or a regional performance email without manual rework.
Diagram: Assurance pipeline (OAAF)
This diagram shows the CI pipeline that validates agents before deployment: unit logic, governance checks, integration routing, chaos tests, evaluation, and health checks.

Orion’s assurance framework is what prevents “agent sprawl” from becoming unmanageable.
What it protects
- Correctness: schema-valid outputs, stable code generation patterns, ground-truth evaluation.
- Governance: privacy checks, audit trail completeness, cost instrumentation.
- Safety: sandbox constraints and code scanning.
- Reliability: chaos testing (garbage input, impossible requests, upstream failures).
- Performance: latency and memory leak checks.
- Safe rollout: shadow mode before full exposure.
Callout: Agents become shippable artifacts
With OAAF gates, an “agent” is treated like a deployable component with tests and SLAs—not a prompt someone tweaked once.
Keeping pricing low while adding value
Orion is designed to control cost through architecture choices rather than hoping users don’t overuse it.
Cost control levers Orion uses
- Smaller prompts through schema injection (agent sees only what it needs).
- Minimal retrieval (only top relevant business rules, not entire documents).
- Bounded self-healing (retry a small number of times, then stop safely).
- Compute where it’s cheapest (SQL engines/warehouses/APIs do aggregation; LLM only compiles the plan).
- Cost tracking end-to-end so optimization is data-driven (per agent, per intent, per tenant/team).
These are the levers that make “agent at scale” financially viable.
Future improvements (turning open questions into a roadmap)
Below are the biggest “next steps” that strengthen determinism, safety, scalability, and cost efficiency while keeping the system easy to operate.
- Upgrade-proof determinism
- Pin AI model versions per environment (dev/stage/prod).
- Add “golden” regression tests that detect changes in generated code and outputs for key questions (revenue, churn, CAC).
- Compare normalized code structures (not just text) to prevent subtle drift.
- Business rule conflict resolution
- Introduce rule priority and governance: owner, effective date, approval state.
- Attach “rule IDs applied” to every execution trace so audits are straightforward.
- Safer, smarter self-healing
- Sanitize error traces before reuse (avoid leaking sensitive tokens/URLs).
- Add circuit breakers for repeated failures and intent-based retry budgets (finance stricter than exploratory queries).
- Tenant-safe long-term memory
- Apply strict access scoping to knowledge retrieval (same rigor as database row security).
- Include retrieval provenance (which knowledge chunks were used) in the audit trail.
- Stronger code safety scanning
- Expand static checks to detect dangerous patterns, not only forbidden imports.
- Introduce risk tiers: different safety policies for read-only queries vs write-capable workflows.
- Caching with correctness guarantees
- Cache common retrieval results and reusable query templates.
- Introduce result caching only with explicit freshness rules (watermarks/invalidation), so cached answers remain trustworthy.
- Risk-based evaluation
- Tighten evaluation gates for finance-grade KPIs (reconciliation tests against trusted BI reports).
- Keep lighter gates for exploratory questions to maintain speed and usability.
- Operational maturity
- “Trace replay” for debugging: reproduce a result using the same context, rules, and schema version.
- Automated rollback on latency/cost regressions, plus progressive rollout (shadow → canary → full).